KR0|关键词总索引
关键词的目标感
关键词的终局是:有没有自然位展示机会 & 有没有自然单。做对关键词,是在扩大“自然入口”;做错关键词,只能用更高成本去补偿,最后表现为 ACOS/TACOS 难降、自然单比例难抬。
当关键词链路被系统化后,订单结构更稳定,也更可放大:
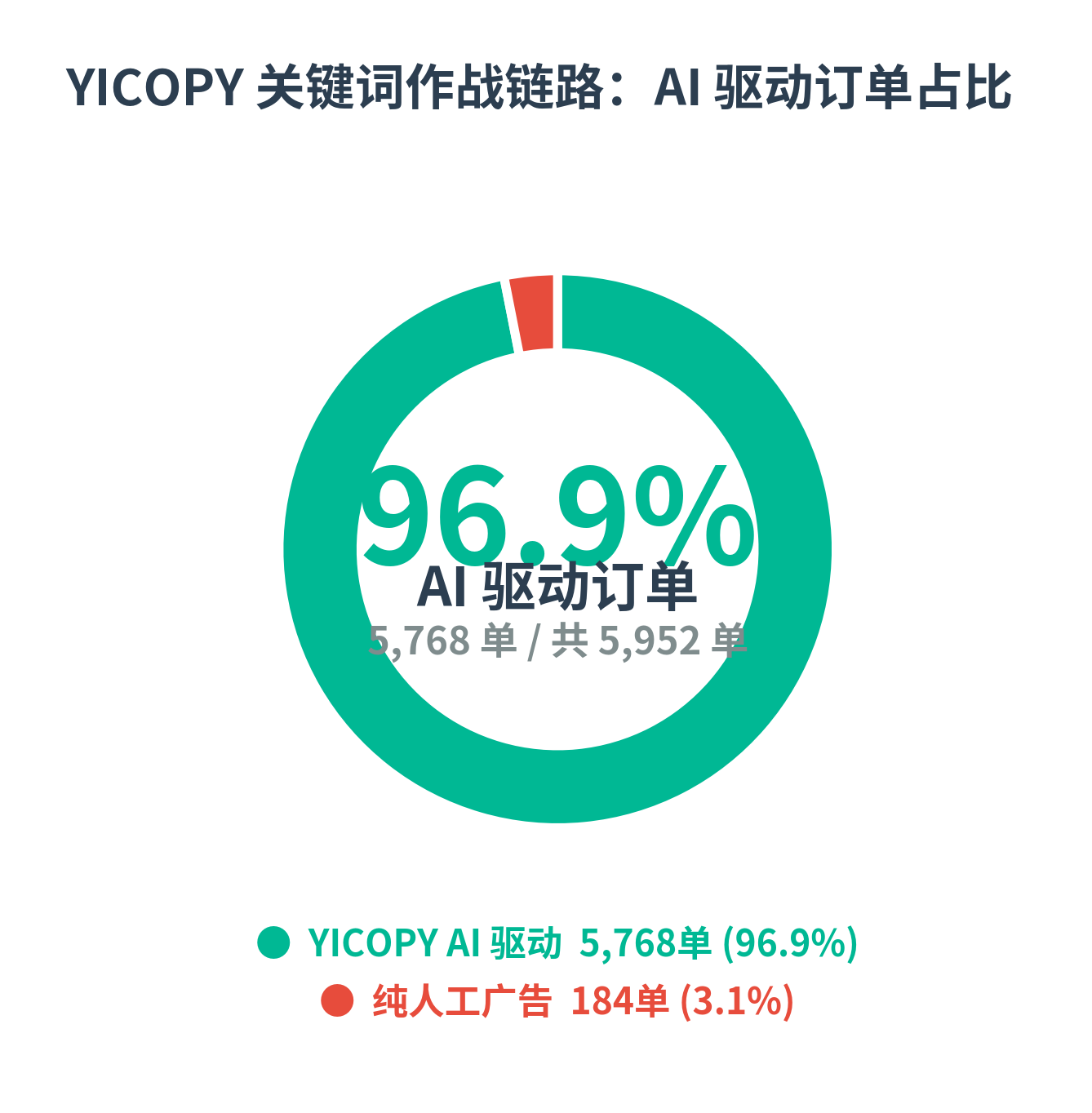
- 总订单:5,952
- 自然订单:4,290(72.1%)
- 广告订单:1,662(27.9%)
- YICOPY 驱动 1,478(占总订单 24.8%;占广告订单 88.9%)
- 人工广告 184(占总订单 3.1%)
从词源到利润闭环
关键词不是一张表,而是一条完整的作战链路:
词源扩容 → 资格验证 → 机会判断 → 文案承接 → 广告放大 → 迭代闭环

YICOPY的关键词模块设计,最终要拿到的不是 2 -3万个候选关键词,而是把关键词从“词表”升级为“可执行词库”:
- 有自然位机会的入口(资格过关)
- 值得花钱打、能带单的入口(机会过关)
- 可直接交给「文案埋词」与「广告冷启动」的精准词包
先讲清:关键词与Listing权重的强关联
Listing 权重 = 亚马逊在不同搜索/意图场景里,愿意给你多少自然展示机会。
- 关键词负责“入口”(产品能进哪些场景)
- 权重负责“分配”(进来后,平台给多少曝光、给到什么位置)
你不需要记算法名,只需要记这条:
入口越多且越有效 → 进入场景越多 → 获得数据越多 → 权重越容易稳定抬升。
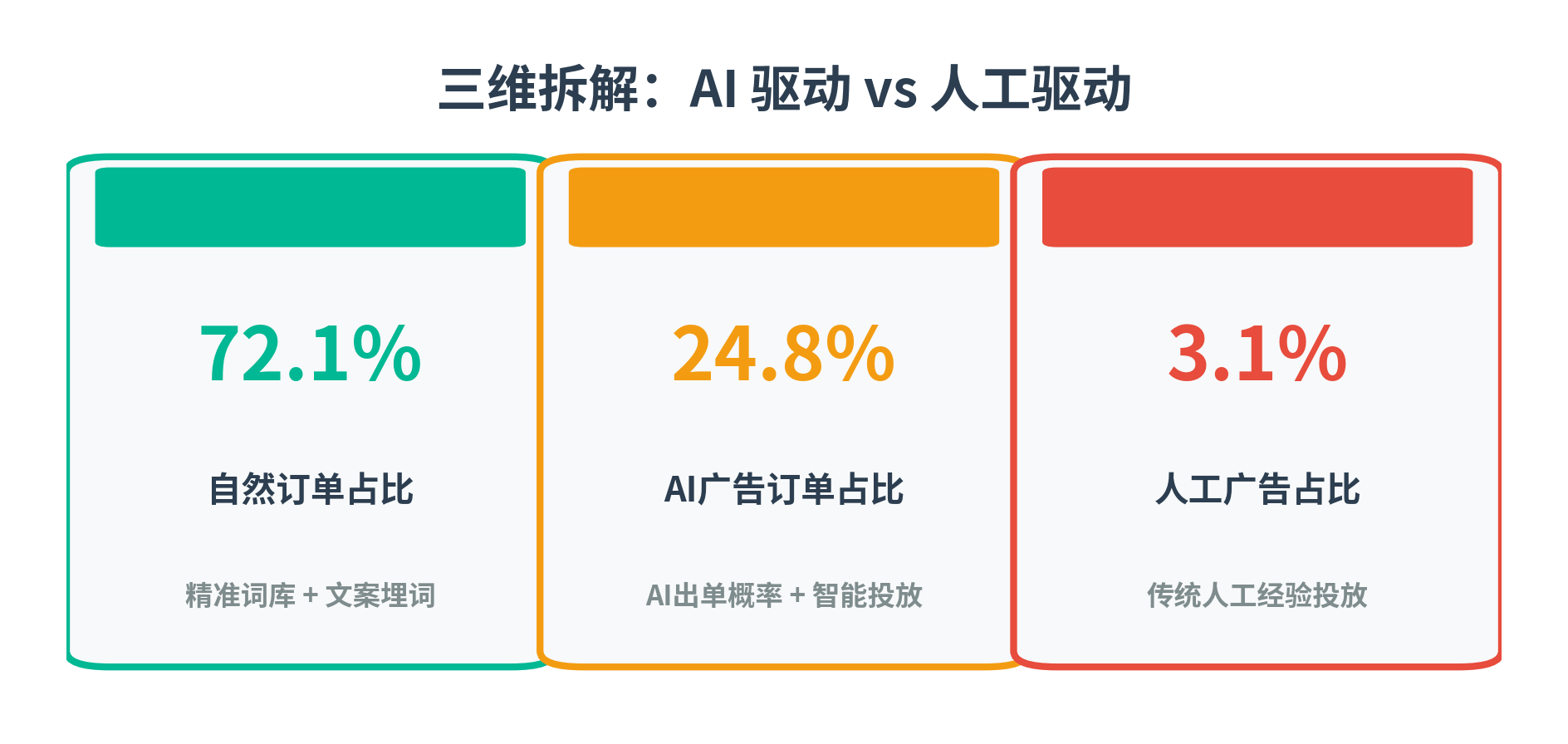
为什么链路会断:入口池不够大 + 可匹配面不够广
链路中任意一环缺失,常见结果是:广告成本上升、自然单承接不足、效率难以稳定改善。根因通常不是“执行不够”,而是上游两项能力不足:
- 入口池:候选入口是否足够丰富(意图/场景/约束表达覆盖)
- 可匹配面:系统是否愿意在更多真实场景召回你的Listing(资格与排序空间)
尤其是,“可匹配面”决定自然入口能不能持续扩大:
为什么品牌ABA / 传统工具拓词在新算法下失效
为便于量化对比,YICOPY采用两个可执行定义:
- 初始关键词库:通过推理模式构建的候选入口集合(先做大入口池)
- 精准关键词库:高收录 × 高出单概率(既有自然曝光资格,也更可能在真实场景中成交)
以 sofa 为例,选取 20 个竞品 ASIN,构建初始词库:
YICOPY的初始推理词库中,包含了大量COSMO关键词。但是,初始词库再大,也不等于自然增长。真正决定增长的是“精准关键词库”有多大:
结论非常清晰:
- ABA数据只剩42个。
- YICOPY = ABA数据的16.69倍。
- Helium 10 = ABA数据的3.09倍。
- 卖家精灵 = ABA的1.88倍。
- 意义:当词源主要依赖「品牌分析ABA」以及「同源的传统拓词软件」时,长尾精准词与意图型表达覆盖不足,导致错失自然流量入口与后续增长空间。
YICOPY的关键词体系:三场仗 + 两道闸门
YICOPY的关键词全链路推理模式与传统关键词软件的效果对比:
YICOPY在关键词模块的组织方式更偏向“作战指挥”:把关键词体系拆成三场仗,并让模块之间能连续衔接:
第一战 | 做大入口池:先发现买家意图词(意向/场景/约束),强调“先发现再验证”。
第二战 | 筛出能打的词:用“收录占比/资格”与“出单概率/机会”把候选词提纯为可执行词库。
第三战 | 让词变成订单:用验证后的词进入文案与投放,减少“写了不收录”的浪费,并通过数据反馈迭代。
注:KR0 的目的,是先把“地图”和“顺序”讲清楚;后续章节再展开验证体系与精准词库。
KR1 | 销词引擎:先把入口池做大,再进入验证
意图推理的入口工程
销词引擎从“买家怎么问、怎么描述需求”的视角,发现更接近转化的入口表达。在 Alexa for Shopping(原 Rufus)等对话式搜索增强的背景下,“意图/场景/约束”类表达的重要性上升:更贴近真实提问方式,也更容易对应到具体购买任务。:
传统关键词软件的拓词方式无法完整覆盖四层:
- 资格(Indexing Eligibility):系统是否“认可”某个词与该 Listing 的关系(决定有没有自然曝光资格)
- 召回(Retrieval):买家输入/提问该表达时,能否进入候选集(决定有没有机会被看到)
- 排序(Ranking):进入候选集后能排到第几(决定自然位与广告位效率)
- 变现(Monetization):以可接受成本换来可持续利润(决定 TACOS、自然单占比与放量空间)
在 AI 搜索趋势下,表达正在从“短词检索”扩展到“意图表达/自然语言提问”。例如 Amazon 的 AI 购物助手 Alexa for Shopping(原 Rufus)支持自然语言对话式提问与推荐,训练数据包括商品目录、评论与问答等。同时,Amazon 也公开过 COSMO 相关的搜索应用研究,强调在电商搜索中进行常识/意图层面的知识生成与服务,并已在搜索应用中部署。
因此,关键词体系如果长期停留在“小样本词源 + 经验筛词”,容易在“入口池”和“可匹配面”上天然受限。
意图推理四步曲
为系统性构建入口池,“意图推理模式R1”的目标是“生成一个覆盖所有潜在购买意图的、结构化的精准流量词包”。将“找词拓词”这一依赖经验和运气的人工筛选工作,升级成一套可重复、可交付的工程流程:
- 兴趣挖掘:将产品背后复杂的购买动机(如人群、场景、痛点、对比、限制条件)解构成结构化的“意图簇”。
- 意图推理:围绕每个“意图簇”,通过AI推理,生成海量符合本地语言习惯和搜索行为的“用户表达”。
- 生成流量词:将这些“用户表达”提纯、去噪、合并,最终输出一个可以直接用于文案埋词和广告投放的“精准流量词包”,含大量的“长尾精准词”和“COSMO类表达”。
- 深度关联:以“意图簇”为核心,进一步扩展同义、变体、场景组合和对比表达,让词库的覆盖面达到最大化。
与传统关键词工具的区别
在亚马逊平台站内流量分发机制逐步向用户购买意图迁移的改变下,对比传统关键词软件的工作差异:
| 区别 | 传统关键词工作流 | YICOPY 词库工程流 |
|---|---|---|
| 工作起点 | 亚马逊品牌分析ABA反查 | 竞品ASIN + AI意图推理 |
| 词库构成 | 主干词 + 少量长尾词 | 主干词 + 海量长尾精准词 + 海量COSMO类表达 |
| 结果导向 | 广告抢夺存量,自然增长乏力 | 广告和自然单双飞,系统性抢夺增量 |
操作流程:构建初始词库(任务 → 结果 → 入库沉淀)
- 步骤1:创建推理任务
- 输入目标竞品ASIN(建议10个以内以确保分析深度)
- 新建挖掘任务,系统自动执行AI分析
- 任务完成后在【详情】查看深度推理结果
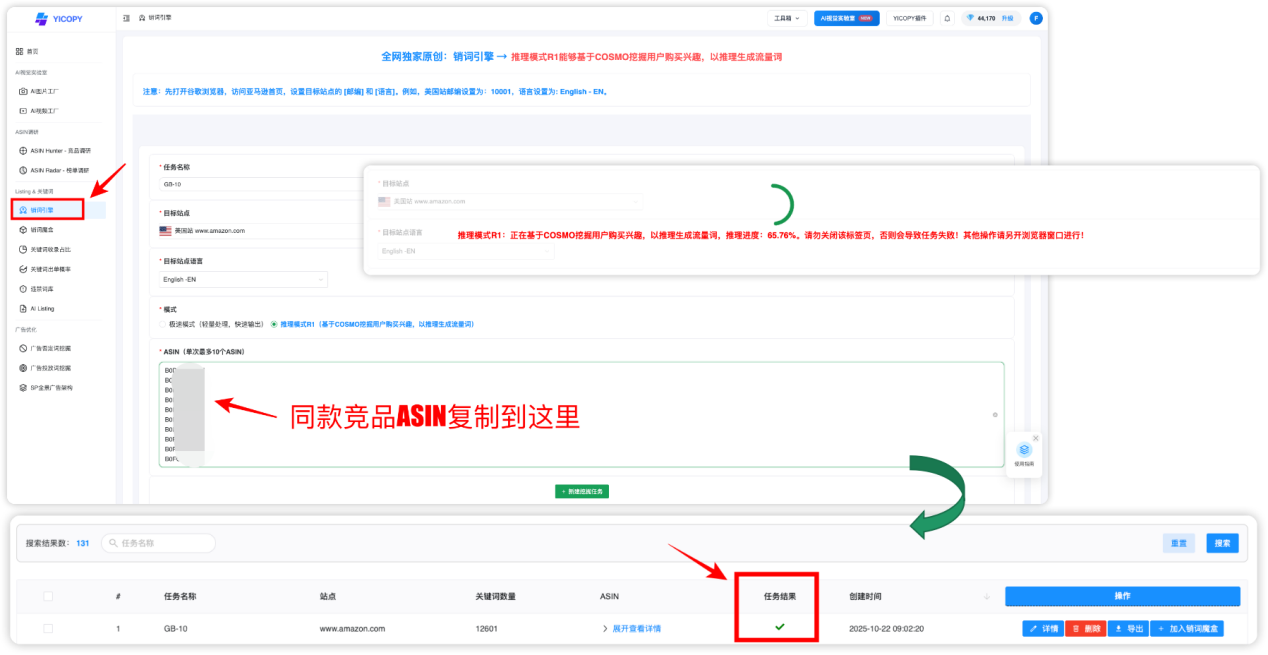
挖掘任务完成后,点击【详情】查看AI深度挖掘出的关键词:
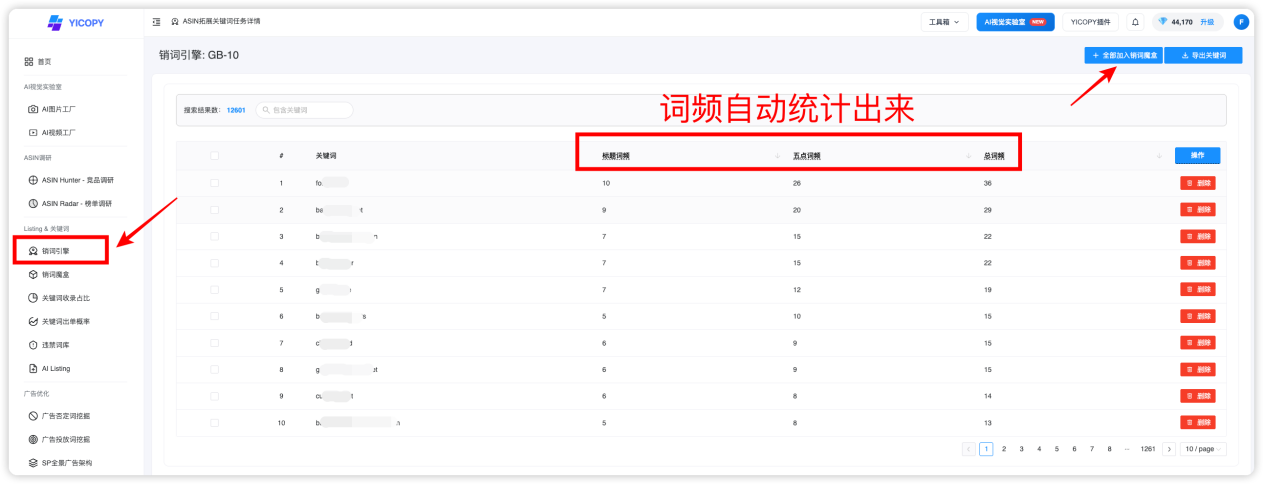
步骤2:多批次任务添加
多次挖掘结果批量添加到销词魔盒,系统自动合并去重:

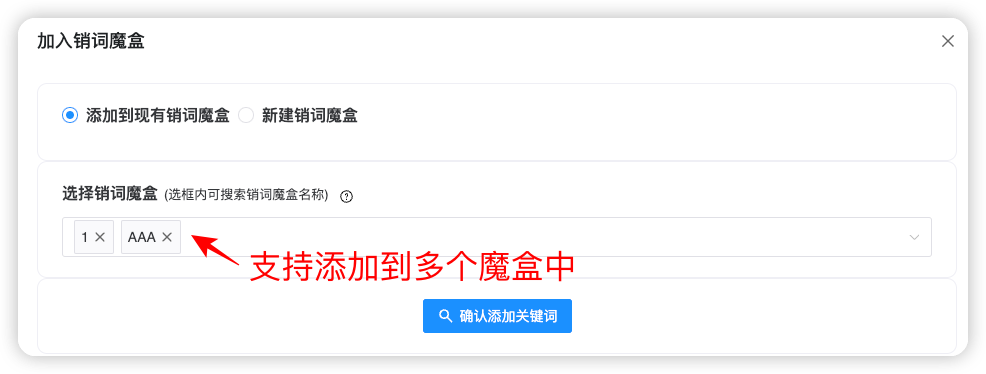
- 支持添加到已有的多个【销词魔盒】中,如下图所示:
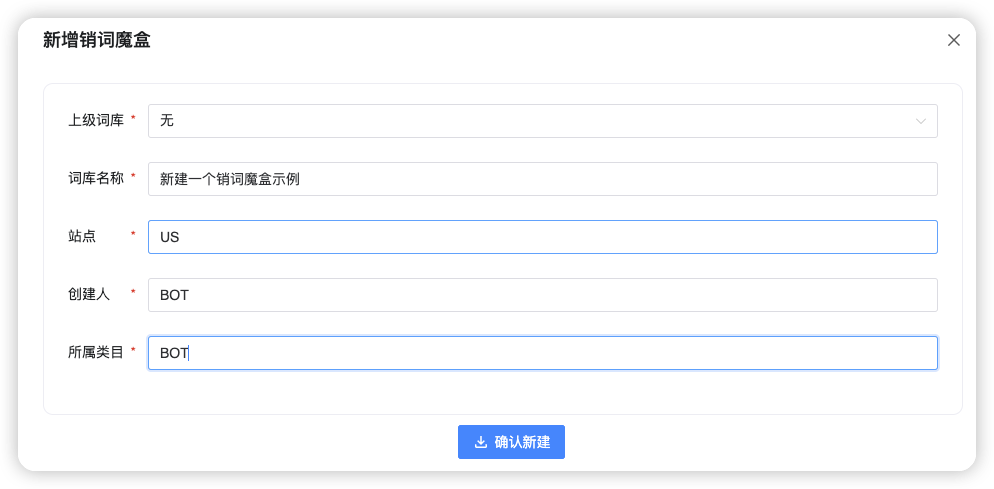
- 也支持新建一个【销词魔盒】,把关键词添加进去:
支持第三方词库合并:多来源合并去重
点击进入【销词魔盒】的【详情】,进入创建的初始关键词库:
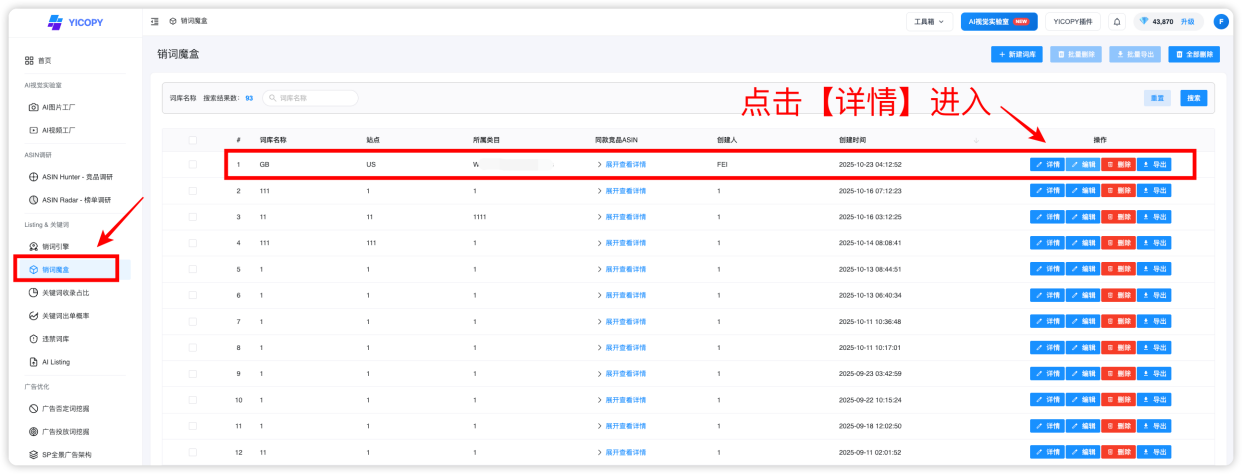
支持导入 ABA / 卖家精灵 / Helium10 等来源,系统自动合并去重:
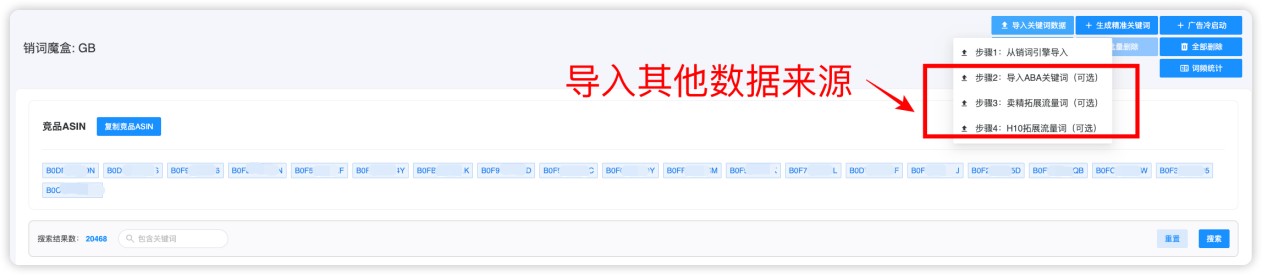
目的:补齐不同数据源的盲区,让入口池更完整。
KR2 | 销词魔盒:销词魔盒:从“2万候选词”到“出单词库”的作战中枢
定位:验证与提纯中心(只做三件事)
关键词在这里完成三件事:
- 管理词库(导入/去重/统计)
- 过闸门(资格 → 机会)
- 出结果(生成精准关键词)
词库管理与优化:把入口池“管起来”
「销词魔盒」让词库从“堆数据”变成“可运营资产”:
- 多来源词库导入(销词引擎 / ABA / Helium10 / 卖家精灵)
- 自动合并去重、词频统计、结构化整理
在【销词魔盒】中,按照下面的操作步骤,点击【新建词库】:
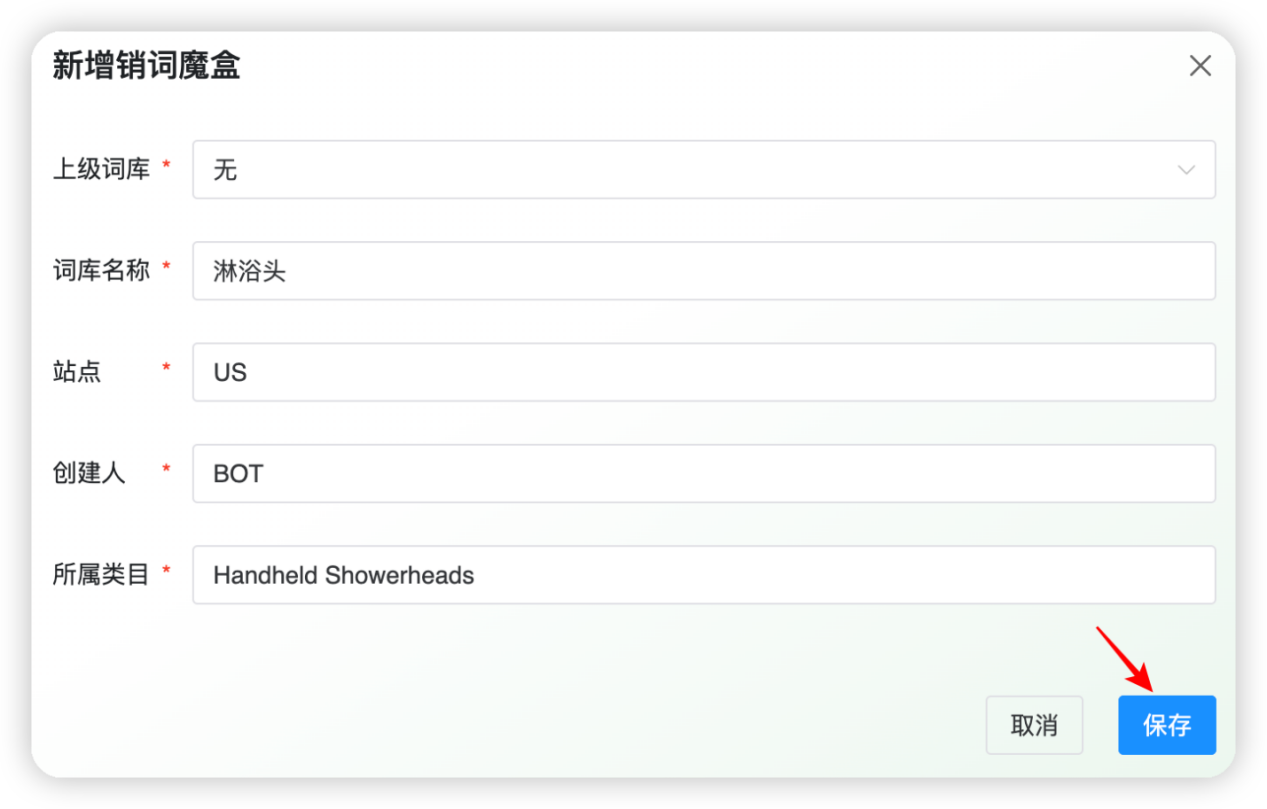
在弹出的对话框中,新建一个 “淋浴头”的词库,输入词库的信息如下,最后点击【保存】:
在【销词魔盒】中,选择“淋浴头”魔盒,点击【详情】,进入该魔盒:

数据导入与整合
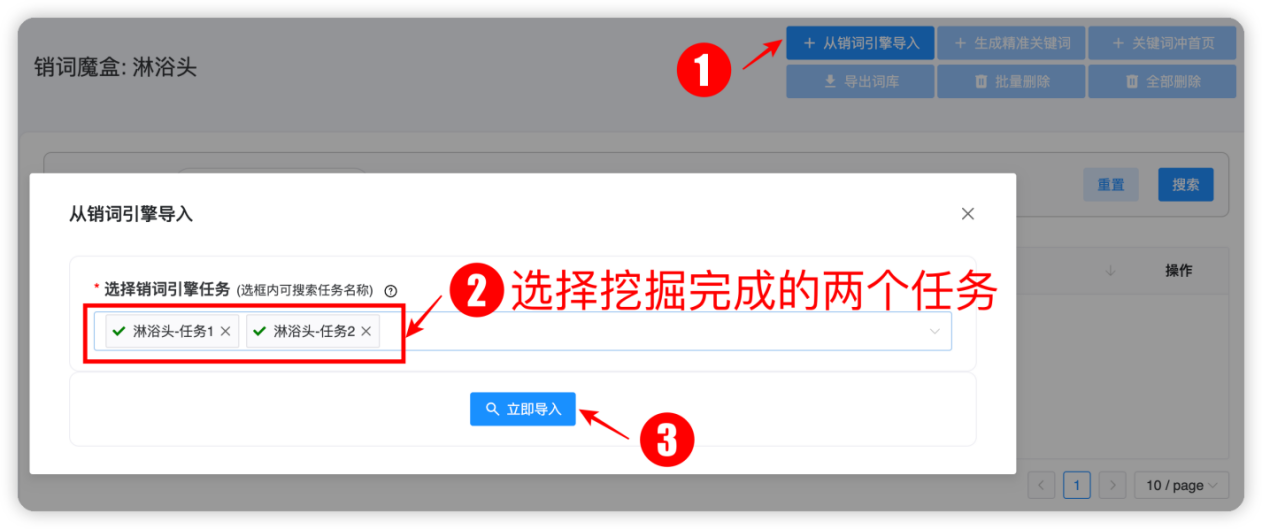
进入魔盒“淋浴头”中,按照下面的操作步骤,选择之前通过【销词引擎】挖掘完成的两个关键词词库,然后点击【立即导入】,如下图所示:
导入完成后,词库如下图所示:
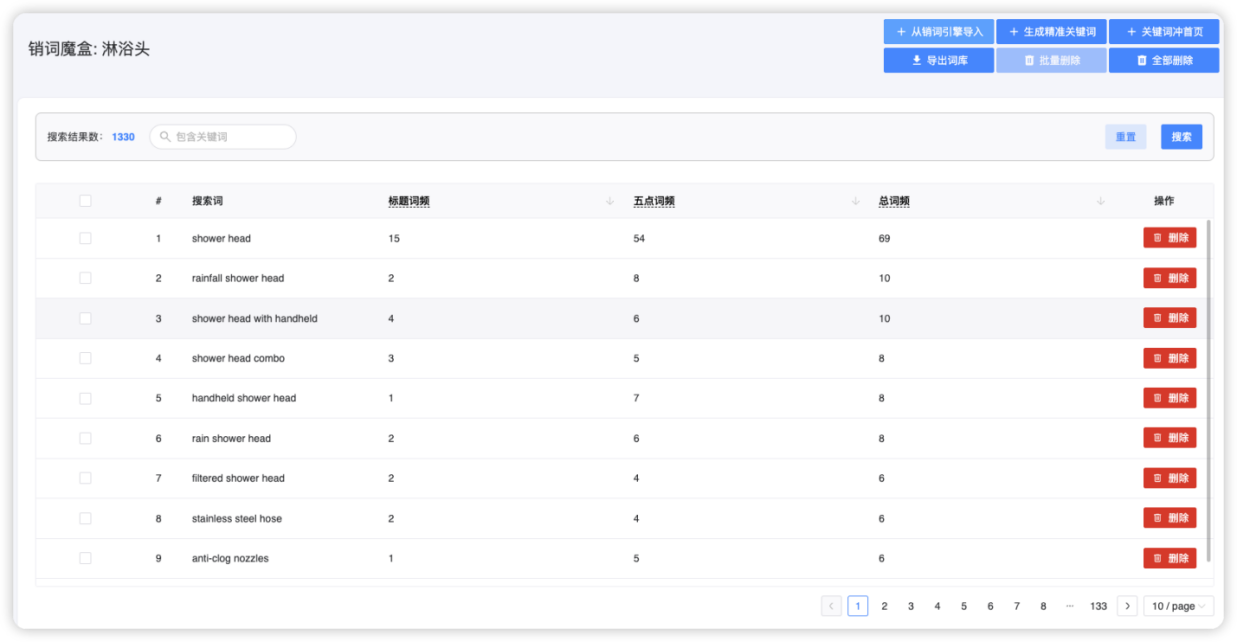
可以看到,在销词魔盒中,关键词的词频统计清晰可见,这是这些关键词在调研的ASIN中出现的词频,包括标题词频、五点词频、以及总词频。
第一闸门:资格验证(决定自然位有没有展示资格)
这一闸门只回答一个问题:关键词是否具备获得自然位展示的资格。如果关键词无法通过该闸门,你的商品在自然位几乎得不到展示,这也是自然单无法提高的根本原因!
操作流程:
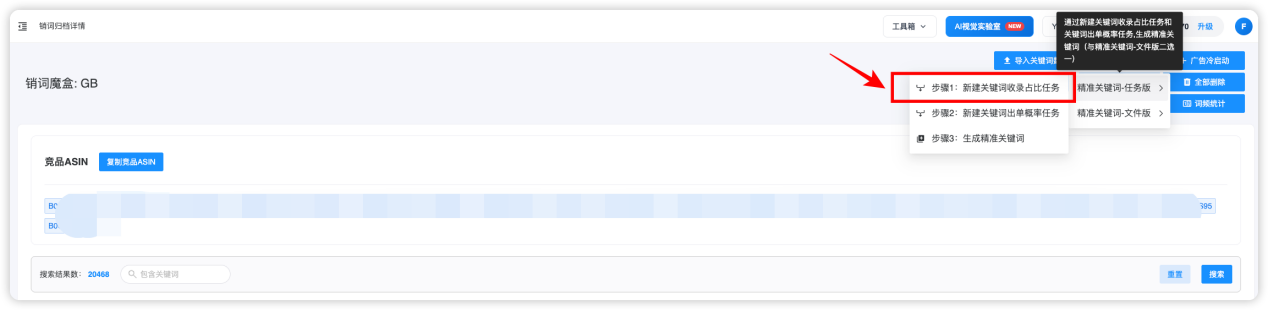
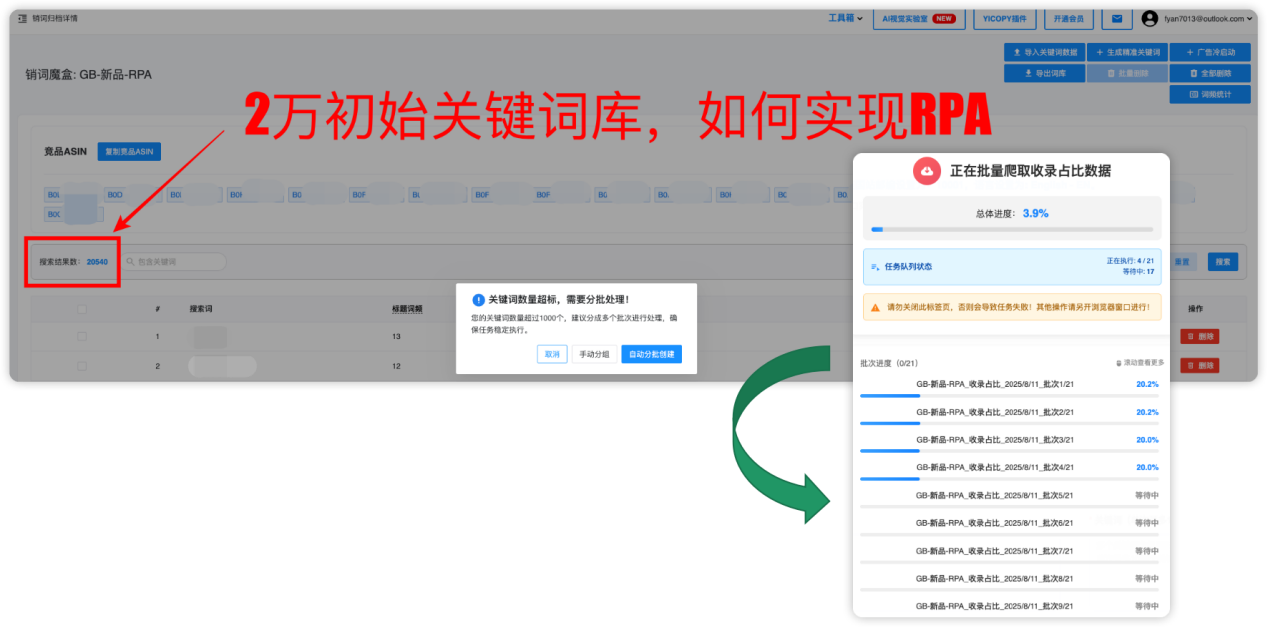
选择需要的【销词魔盒】进入到初始关键词库,点击【步骤1:新建关键词收录占比任务】:
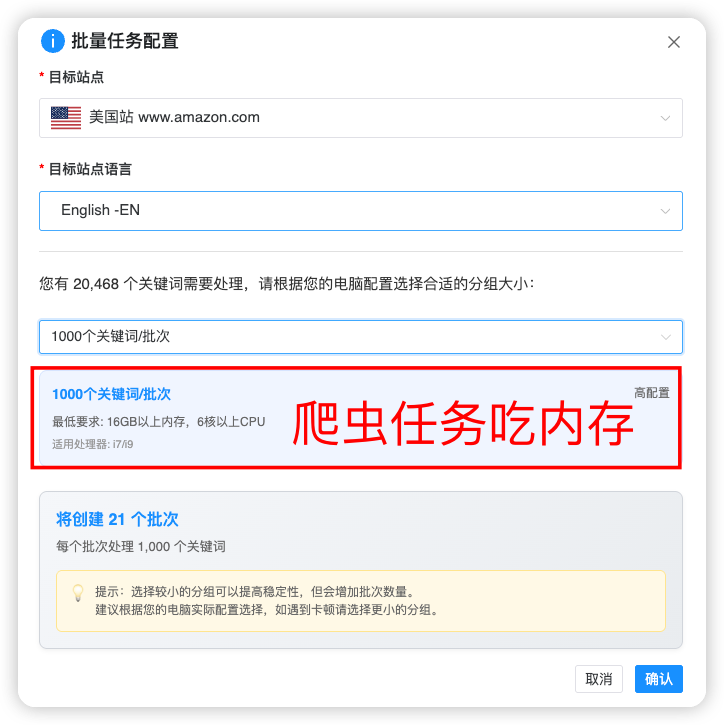
弹出的对话框,点击【自动分批创建】:
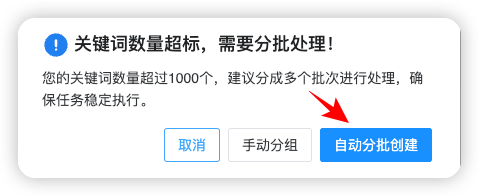
可以根据电脑配置,选择单批次任务的关键词数量,会创建前端爬虫任务,这个主要耗内存:
任务启动后,界面如下图:
等待任务完成后,会显示绿色对号,如下图所示:
第二闸门:机会验证(决定值不值得打)
这一闸门只回答一个问题:这个词是否具备成交潜力,是否值得投入预算与资源。
操作流程:
选择需要的【销词魔盒】进入到初始关键词库,点击【步骤2:新建关键词出单概率任务】:
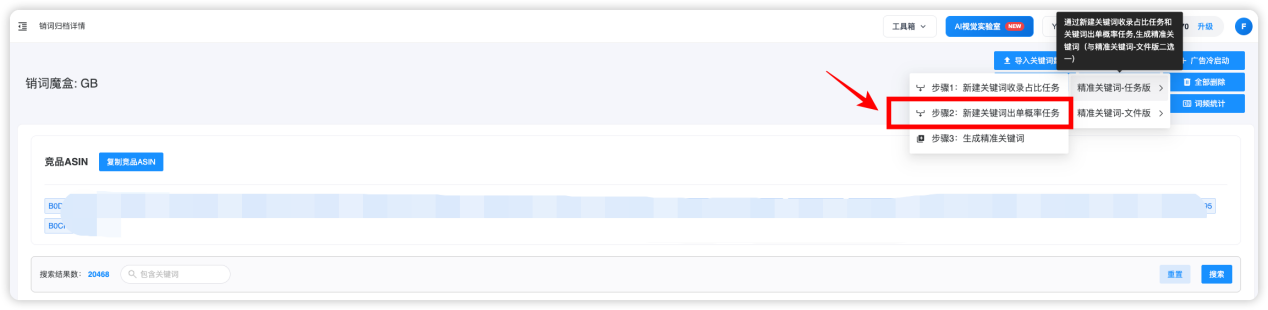
弹出的对话框,点击【自动分批创建】:
可以根据电脑配置,选择单批次任务的关键词数量,会创建前端爬虫任务,这个主要耗内存:
后续操作步骤与【收录占比任务】一样,等待任务完成即可。
精准关键词生成(2万 → 706)
当两类任务完成后:
选择全部任务 → 点击【生成精准关键词】→ 得到可执行词库:
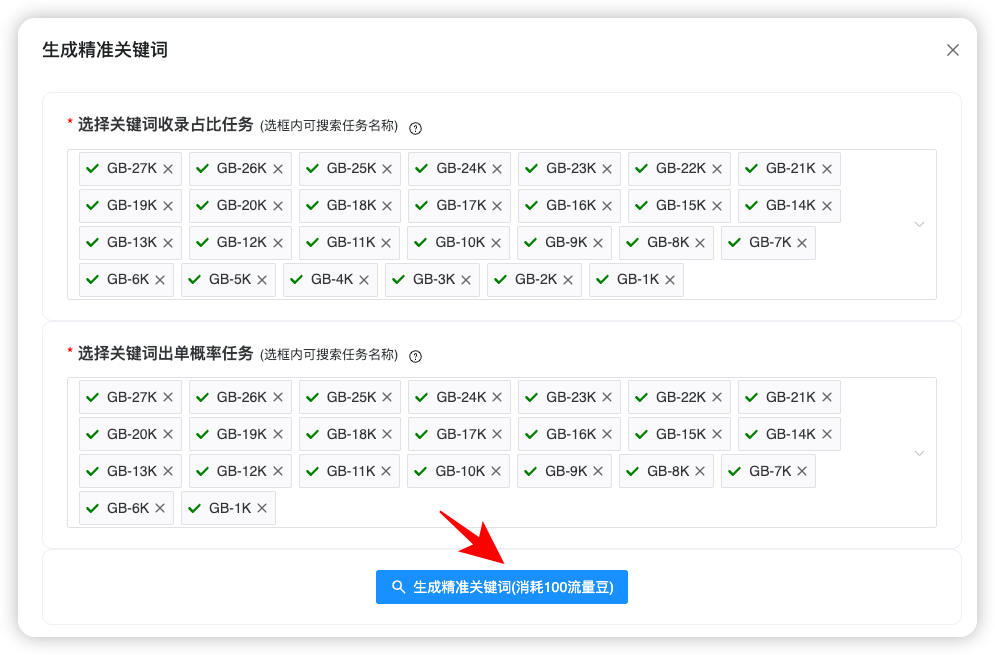
系统自动根据亚马逊站内流量分配机制,筛选精准关键词。在弹出的新对话框中,点击按钮【继续生成】,如下图所示:
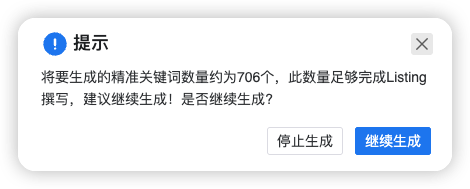
最后得到精准关键词706个,如下图所示:
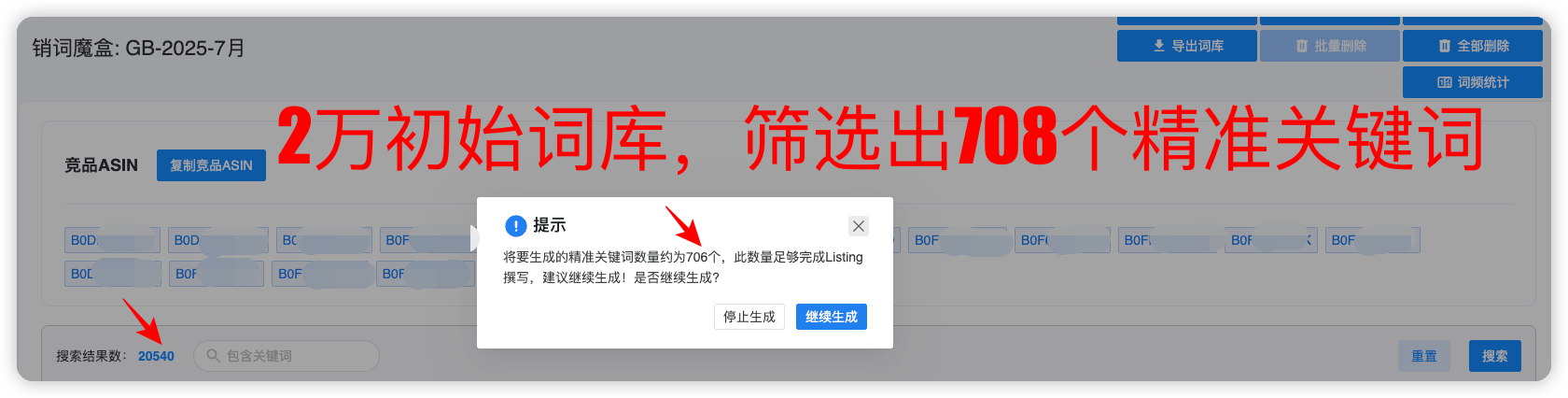
一句话记忆点:把入口池提纯成:有自然位机会 + 有成交潜力 的词包。
精准词应用场景A:文案埋词(让Listing“被系统认可”)
目标: 提升收录与召回,让 Listing 在更多真实场景里“能被找得到”。
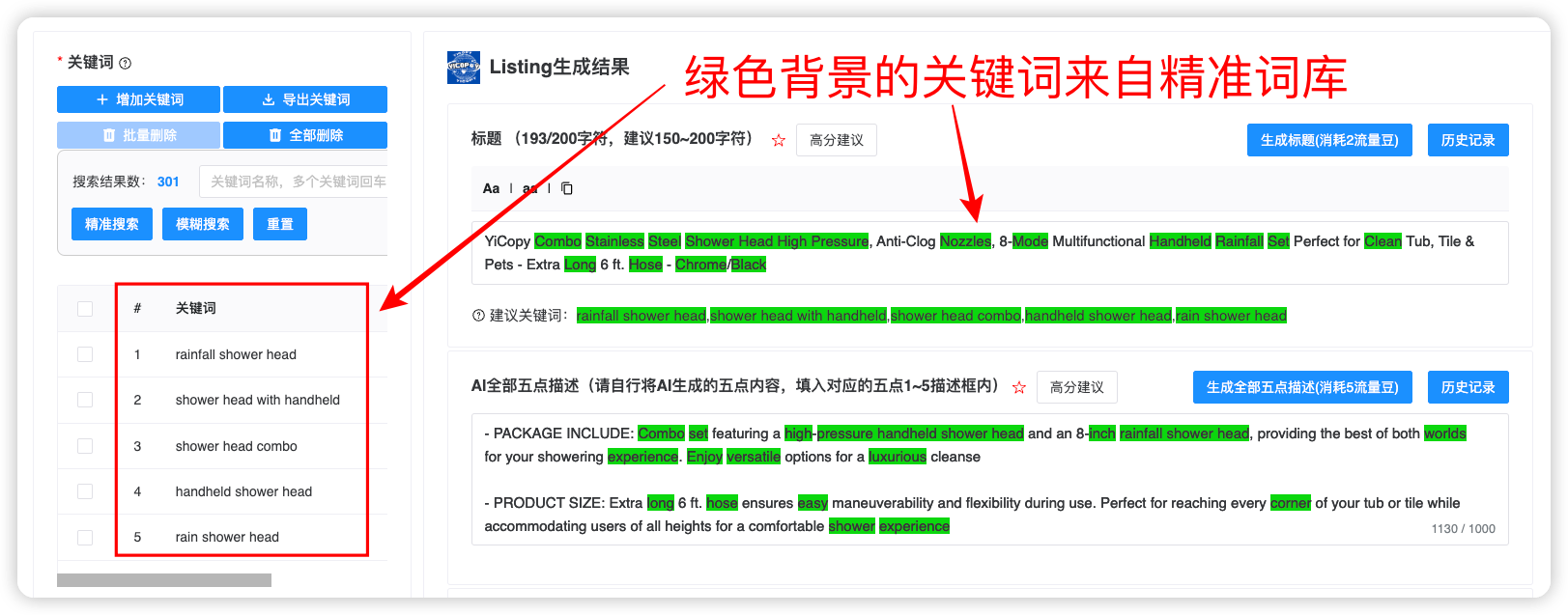
操作要点(只做 3步):
- 关键词分层(先分工再上文案)
- 核心词:决定主意图(1 组)
- 场景/约束词:决定长尾入口(多组)
- 变体词:同义、拼写、组合表达(补覆盖)
- 槽位分配(把词放到最该出现的位置)
- Title:放“核心意图 + 关键差异点”(少而准)
- Bullets:每条绑定 1 个“意图簇”(让段落有任务)
- Backend Search Terms:放“可收录但不适合正文堆”的词(补覆盖)
- A+/QA:放更自然的场景表达(承接长尾与对话式表达)
- 发布后校验(用结果反推文案)
- 先看:收录覆盖是否达标(没收录=白写)
- 再看:自然位是否能稳定进入可见区间(能见=才有增长)
一句话总结:精准词先解决“资格与召回”,文案再解决“转化与说服”。
精准词应用场景B:广告冷启动(让词尽快“带单”,而不是烧钱)
目标: 用最小试错成本,把“能打的词”快速跑出订单与可复制结构。
新品推广中,精准关键词可以直接用户广告冷启动:

常见误区:为什么“越做越贵、自然单起不来”
误区 1:把“初始词库”当“精准词库”
典型表现:
- 词很多,看起来很努力,但自然位起不来
- 广告越投越散,ACOS/TACOS 下不去
本质原因:
- 初始词库只是“入口候选”,并不等于系统认可、更不等于会成交
- 没有跑“资格(收录)+机会(出单概率)”,就等于拿“未验证入口”去烧预算
正确做法:
- 先做大入口池,再用两道闸门提纯:
- 收录占比(资格)→ 出单概率(机会)→ 生成精准关键词
只有“精准词”才进文案与主力投放
误区 2:先写文案再验证收录(写完才发现“不收录”)
典型表现:
- 文案写得很满,实际收录很少
- 以为是广告不给力,结果是“系统根本不认你写的入口”
本质原因:
- 文案是“承接器”,不是“造入口器”
- 入口没资格,承接再好也接不到自然流量
正确做法:
- 顺序必须反过来:
- 先验证收录 → 再分配槽位 → 再写承接文案
一句话记住:先让系统认,再让买家信